
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- chart.js
- 폼메일
- roundcube
- 자바스크립트
- Mail Server
- Android
- not working
- 우분투
- 안드로이드 푸시
- C#
- html5
- android 효과음
- javascript
- mysql
- curl
- 설치
- 안드로이드 푸쉬
- UML
- xe
- PHP
- WebView
- dovecot
- C# IO
- 자동 생성
- 안드로이드 gcm
- soundpool
- php 취약점
- FCM
- php 시큐어코딩
- 안드로이드
- Today
- Total
그러냐
(미완)yolo v7 로컬에서 학습 데이터 만들기 (2) (yolov7 네트워크 설정 및 훈련) 본문
https://kyoungin90.tistory.com/498
yolo v7 로컬에서 학습 데이터 만들기 (1) (환경설정, 이미지데이터 다운 후 라벨링 하기)
https://www.youtube.com/watch?v=-QWxJ0j9EY8 ※ 기초부터 알고 따라하는 것이 아니라 중간중간 잘못된 설명이 있을 수도 있습니다 ※ 다음 유튜브를 보고 YOLO v7을 colab이 아닌 로컬컴퓨터(개인컴퓨터)에서
kyoungin90.tistory.com
이전글에서 이미지를 다운받고 yolo 포멧으로 주석을 달아 train과 val 데이터세트를 만들었다. 이제는 yolov7 네트워크를 다운받아 컴퓨터에 설치해줘야한다.
다음 github에서 오른쪽 code를 눌러 zip 파일을 이미지가 저장된 파일에 다운받는다.
https://github.com/WongKinYiu/yolov7
GitHub - WongKinYiu/yolov7: Implementation of paper - YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time
Implementation of paper - YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors - GitHub - WongKinYiu/yolov7: Implementation of paper - YOLOv7: Trainable bag-of...
github.com

압축을 풀어준 뒤 파일들이 있는 폴더를 yolov7-custom으로 바꿔준다.

다운받은 폴더에 들어가보면 yolov7을 동작하기 위한 파일들이 정리되어있다. 이중 requirements.txt를 열어보면 yolov7을 동작하기 위한 라이브러리들의 버전이 들어있다. (나중에 프로그램을 실행하면 txt에 있는 환경설정값이 자동으로 들어가서 파일을 설치한다)

이 리스트에서 현재 파이토치와 파이토치비전을 따로 설치해주기 위해서 기존의 requirements에 있는 torch와 torchvision값을 지워준다. 그리고 같은 폴더에서 requirements_gpu.txt를 만들어준다.
파이토치 홈페이지에 들어가서 이전버전의 파이토치를 다운받을 수 있는 곳으로 간다. ( 이전버전을 다운받는 이유는 최신버전 혹은 너무 낮은버전의 파이토치는 yolov7에서 잘 작동하지 않기 때문이다. 여기에서는 1.11.0버전을 다운받아주었다.)
https://pytorch.org/get-started/previous-versions/
PyTorch
An open source machine learning framework that accelerates the path from research prototyping to production deployment.
pytorch.org
v1.11.0 버전 중에서 자신의 쿠다CUDA버전을 확인한 후에 맞는 토치의 명령어를 복사해서 requirements_gpu에 복사해준다. ( cuda 버전확인은 프롬프트 창에서 nvcc --version을 입력하면 알 수 있다)



쿠다설치 명령어를 복사한뒤 다음과 같은 형식으로 바꿔서 저장해준다.

그다음 프롬프트창에서 requirements.txt가 위치한 곳으로 이동한 다음 pip install -r requirements.txt 를 이용해 requirements에 있던 라이브러리를 설치해준다. ( -r 은 pip에서 requirement파일 형태라고 지정해주는 코드이다) 1)
pip install -r requirements.txt
그 다음 같은 방법으로 requirements_gpu.txt 를 설치해준다. pip install -r requirements_gpu.txt
pip install -r requirements_gpu.txt
이미지와 레이블 데이터가 들어있는 train 과 val 폴더를 yolov7-custom의 data폴더 안으로 넣어준다.

기존에 있던 coco.yaml 파일을 복사하여 custom_data.yaml로 바꿔준뒤 안의 내용을 우리가 훈련시킨 클래스로 변경시켜야한다. 기존 coco데이터는 80개의 물체를 인식할 수 있도록 만들어져있는데 이것을 우리에게 맞는 내용을 바꿔야한다.
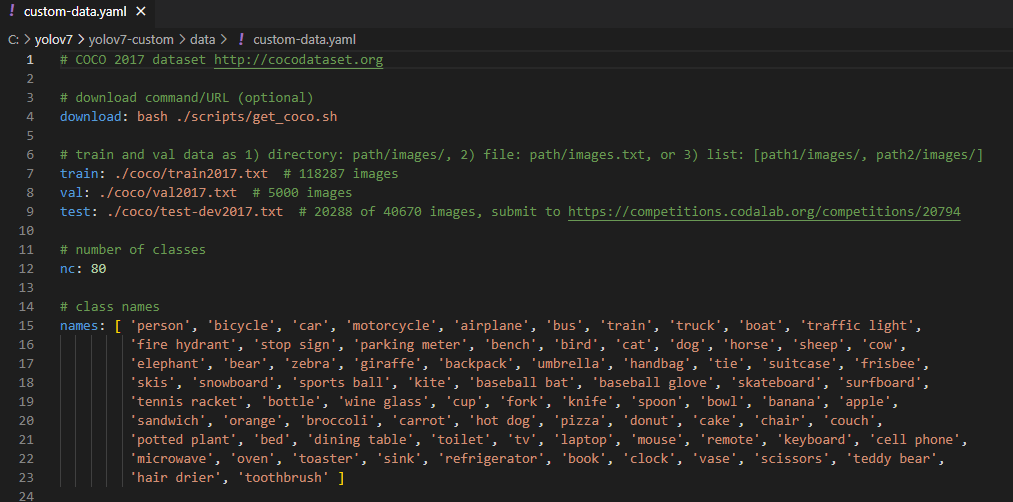
train 데이터는 yolov7이 실행되는 파일기준으로 data안의 train에 들어있고 val 파일은 data의 val저장되어 있다. 이미지에 레이블링된 물체의 갯수는 1개이고 클래스의 이름은 순서대로 지정되었다. ( 이름의 형식이나 클래스의 숫자가 다르면 학습중에 오류가 생긴다)

그다음 yolov7-custom 에서 cfg (configuration(구성)의 약자) 로 들어가서 training을 보면 다양한 형태의 yolov7을 볼 수 있다. 각 네트워크의 차이는 중간에 처리되는 노드들의 형태나 갯수들을 달리해서 정확도를 높이거나, 가볍게 만들어 속도를 높여서 사용하려는 목적에 맞는 네트워크를 선택할 수 있다.


각 네트워크의 성능차이
더많은 네트워크는 yolov7 github에서 오른쪽 release를 눌러 assets를 열어보면 추가적인 네트워크를 확인할 수 있다.

가장 기본적인 네트워크인 yolov7을 복사한 다음 yolov7-custom으로 이름을 바꿔주고 안에 있는 nc 를 우리가 이전에 변경한 클래스 숫자와 맞춰준다. (여기에선 80 -> 1 로 변경 ) (여기에서 만들어지는 네트워크의 구조에 따라 yolov7의 성능이 달라진다)


위 github에서 위에서 설정한 네트워크의 weight을 yolov7-custom폴더에 다운받는다. ( performance의 model에서 각 이름을 선택하면 .pt형식의 파일이 다운받아진다)

각 네트워크의 성능차이

훈련시키기
이제 훈련에 필요한 모든 자료를 만들었으니 훈련을 시킬 수 있다. 프롬프트 창에서 다음과 같이 입력하여 훈련을 시킬 수 있다.
python train.py --workers 1 --device 0 --batch-size 8 --epochs 100 --img 640 640 --data data/custom_data.yaml --hyp data/hyp.scratch.custom.yaml --cfg cfg/training/yolov7-custom.yaml --name yolov7-custom --weights yolov7.ptpython train.py 파이썬으로 train.py를 실행하고 train.py에 있는 설정값을을 지정해주었다.
--workers 1 : 컴퓨터 한대
--device 0 : 현재 사용하고 컴퓨터에 연결된 장비 - 그래픽카드번호
--batch-size 8 : 배치사이즈 - 한번에 연산하는 데이터의 크기 클수록 빨리되지만 하드웨어 성능이 받쳐줘야한다.
--epochs 100 : epochs 횟수
--img 640 640 : 학습되는 이미지의 크기 각 네트워크마다 고정된 값이 있다.
--data data/custom_data.yaml : 데이터가 있는 정보 yaml의 위치
--hyp data/hyp.scratch.custom.yaml : 하이퍼파리미터 정보가 있는 yaml의 위치
--cfg cfg/training/yolov7-custom.yaml : cfg 정보가 있는 yaml의 위치
--name yolov7-custom : 저장위치
--weights yolov7.pt : weight값의 위치
학습중간에 메모리가 없어서 멈출수도 있다.

코드가 실행되면 지정된 네트워크가 만들어지고 변수가 입력된다.

이미지데이터로 모아둔 80개의 훈련데이터와 11개의 val 파일이 선택된다음 훈련이 시작된다.

지정된 batch사이즈와 epoch의 크기에 따라 훈련이 된다.

훈련이 완료된 뒤에는 run 이란 폴더의 train에 훈련결과와 최적 weight 등이 저장된다. (훈련이미지에 중복이 많아서 그런지 성능이 좋지 않게 나왔다)



weight 폴더로 들어가 내 데이터세트에 맞게 훈련된 best.py 를 yolov7-custom으로 가져온다음 detect.py를 실행시켜 성능을 테스트 할 수 있다.
단일이미지를 테스트하기위해 프롬프트 창에서 다음과 같은 명령어를 입력해준다. source 부분에 분석하고자 하는 이미지의 이름을 넣어준다. (동영상을 테스트 하기 위해서는 source부분에 mp4형식의 동영상이름을 넣어준다)
python detect.py --weights best.pt --conf 0.5 --img-size 640 --source test.jpg --view-img --no-trace
테스트된 이미지는 runs 에서 detect 폴더에 저장된다.
개발노트
훈련이미지가 적어서(50) 그런지 네트워크의 성능이 좋지 않다. (유튜브와 똑같이 한것 같은데 성능이 다르다. 댓글을 봐도 비슷하게 성능이 나오지 않았다는 글이 있는데 학습이미지를 더 추가하라는 말만 있다)
1)
epoch를 늘려봤는데 오히려 성능이 낮아졌다.


2) 파이토치 낮은버전을 덮어 씌웠다가 명령어를 실행하니 오류가 생김

3)
로컬에서는 예제파일이 동작하지 않는데 colab에서는 잘 작동함, colab에서는 기존 coco weight을 사용하면 박스가 만들어진다. (내가 훈련시킨 데이터로를 박스가 만들어지지 않는다) (로컬에서는 horse로 해도 만들어지지 않는다)

4)
구글 colab에서 훈련시키면 훈련이 잘되고 이미지에 박스가 잘 만들어진다. (훈련이 잘 되지않으면 마킹이 잘 되지 않는다고 하는데 로컬에서 박스가 안쳐지는 것은 다른 문제가 있는 것 같다.)


5) colab에서 작업시 585 error

https://github.com/WongKinYiu/yolov7/issues/1045

loss.py의 내용을 변경해주니 작동했다.
6)
로컬에서 박스가 만들어지지 않았는데 웹캠으로 설정하고 (--source 를 0 으로 설정, detect.py에 가보면 설정을 확인할 수 있다.) 이런저런 움직임을 해보니 박스가 만들어졌다. (박스가 안만들어지는 것이 훈련이 잘못되서 그런걸까? 그럼 왜 미리 훈련된 말에서는 안됐을까)

7)
박스가 보이지 않는 결과를 웹캠을 이용하여 보면 잘 작동한다.(분석하고 저장하는 과정에서 문제가 생기는 것 같다.)

참고
1)
https://pip.pypa.io/en/stable/user_guide/
User Guide - pip documentation v22.3.1
python -m pip python -m pip executes pip using the Python interpreter you specified as python. So /usr/bin/python3.7 -m pip means you are executing pip for your interpreter located at /usr/bin/python3.7. py -m pip py -m pip executes pip using the latest Py
pip.pypa.io
'AI' 카테고리의 다른 글
| How to convert pt to tflite (yolov5 to tensorflow lite) tflite로 변환 (0) | 2023.08.21 |
|---|---|
| yolo v7 로컬에서 학습 데이터 만들기 (1) (환경설정, 이미지데이터 다운 후 라벨링 하기) (0) | 2023.08.21 |

